The key to developing flexible machine-learning models that are capable of reasoning like people do may not be feeding them oodles of training data. Instead, a new study suggests, it might come down to how they are trained. These findings could be a big step toward better, less error-prone artificial intelligence models and could help illuminate the secrets of how AI systems—and humans—learn.
Humans are master remixers. When people understand the relationships among a set of components, such as food ingredients, we can combine them into all sorts of delicious recipes. With language, we can decipher sentences we’ve never encountered before and compose complex, original responses because we grasp the underlying meanings of words and the rules of grammar. In technical terms, these two examples are evidence of “compositionality,” or “systematic generalization”—often viewed as a key principle of human cognition. “I think that is the most important definition of intelligence,” says Paul Smolensky, a cognitive scientist at Johns Hopkins University. “You can go from knowing about the parts to dealing with the whole.”
True compositionality may be central to the human mind, but machine-learning developers have struggled for decades to prove that AI systems can achieve it. A 35-year-old argument made by the late philosophers and cognitive scientists Jerry Fodor and Zenon Pylyshyn posits that the principle may be out of reach for standard neural networks. Today’s generative AI models can mimic compositionality, producing humanlike responses to written prompts. Yet even the most advanced models, including OpenAI’s GPT-3 and GPT-4, still fall short of some benchmarks of this ability. For instance, if you ask ChatGPT a question, it might initially provide the correct answer. If you continue to send it follow-up queries, however, it might fail to stay on topic or begin contradicting itself. This suggests that although the models can regurgitate information from their training data, they don’t truly grasp the meaning and intention behind the sentences they produce.
But a novel training protocol that is focused on shaping how neural networks learn can boost an AI model’s ability to interpret information the way humans do, according to a study published on Wednesday in Nature. The findings suggest that a certain approach to AI education might create compositional machine learning models that can generalize just as well as people—at least in some instances.
“This research breaks important ground,” says Smolensky, who was not involved in the study. “It accomplishes something that we have wanted to accomplish and have not previously succeeded in.”
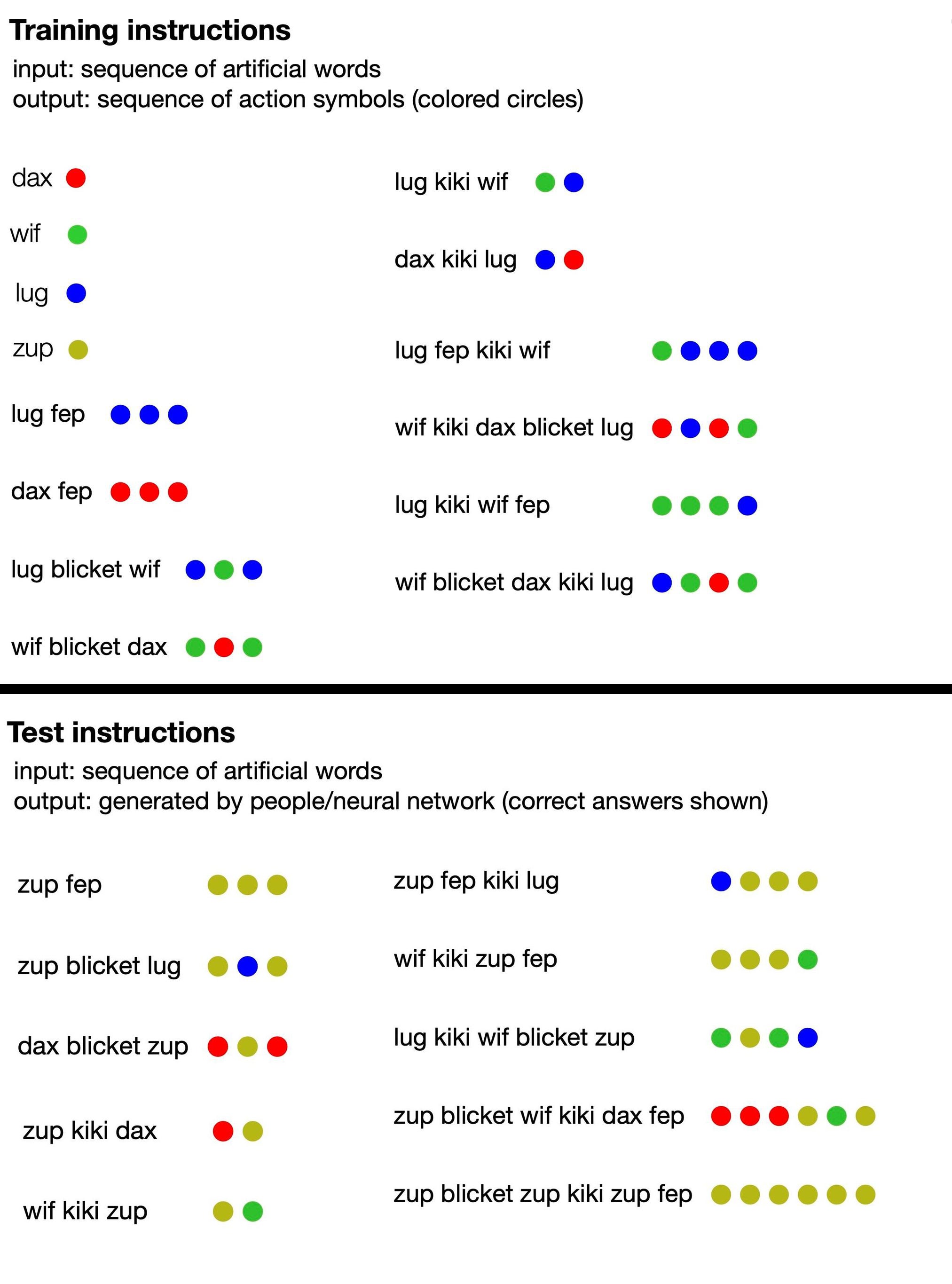
To train a system that seems capable of recombining components and understanding the meaning of novel, complex expressions, researchers did not have to build an AI from scratch. “We didn’t need to fundamentally change the architecture,” says Brenden Lake, lead author of the study and a computational cognitive scientist at New York University. “We just had to give it practice.” The researchers started with a standard transformer model—a model that was the same sort of AI scaffolding that supports ChatGPT and Google’s Bard but lacked any prior text training. They ran that basic neural network through a specially designed set of tasks meant to teach the program how to interpret a made-up language.
The language consisted of nonsense words (such as “dax,” “lug,” “kiki,” “fep” and “blicket”) that “translated” into sets of colorful dots. Some of these invented words were symbolic terms that directly represented dots of a certain color, while others signified functions that changed the order or number of dot outputs. For instance, dax represented a simple red dot, but fep was a function that, when paired with dax or any other symbolic word, multiplied its corresponding dot output by three. So “dax fep” would translate into three red dots. The AI training included none of that information, however: the researchers just fed the model a handful of examples of nonsense sentences paired with the corresponding sets of dots.
From there, the study authors prompted the model to produce its own series of dots in response to new phrases, and they graded the AI on whether it had correctly followed the language’s implied rules. Soon the neural network was able to respond coherently, following the logic of the nonsense language, even when introduced to new configurations of words. This suggests it could “understand” the made-up rules of the language and apply them to phrases it hadn’t been trained on.
Additionally, the researchers tested their trained AI model’s understanding of the made-up language against 25 human participants. They found that, at its best, their optimized neural network responded 100 percent accurately, while human answers were correct about 81 percent of the time. (When the team fed GPT-4 the training prompts for the language and then asked it the test questions, the large language model was only 58 percent accurate.) Given additional training, the researchers’ standard transformer model started to mimic human reasoning so well that it made the same mistakes: For instance, human participants often erred by assuming there was a one-to-one relationship between specific words and dots, even though many of the phrases didn’t follow that pattern. When the model was fed examples of this behavior, it quickly began to replicate it and made the error with the same frequency as humans did.
The model’s performance is particularly remarkable, given its small size. “This is not a large language model trained on the whole Internet; this is a relatively small transformer trained for these tasks,” says Armando Solar-Lezama, a computer scientist at the Massachusetts Institute of Technology, who was not involved in the new study. “It was interesting to see that nevertheless it’s able to exhibit these kinds of generalizations.” The finding implies that instead of just shoving ever more training data into machine-learning models, a complementary strategy might be to offer AI algorithms the equivalent of a focused linguistics or algebra class.
Solar-Lezama says this training method could theoretically provide an alternate path to better AI. “Once you’ve fed a model the whole Internet, there’s no second Internet to feed it to further improve. So I think strategies that force models to reason better, even in synthetic tasks, could have an impact going forward,” he says—with the caveat that there could be challenges to scaling up the new training protocol. Simultaneously, Solar-Lezama believes such studies of smaller models help us better understand the “black box” of neural networks and could shed light on the so-called emergent abilities of larger AI systems.
Smolensky adds that this study, along with similar work in the future, might also boost humans’ understanding of our own mind. That could help us design systems that minimize our species’ error-prone tendencies.
In the present, however, these benefits remain hypothetical—and there are a couple of big limitations. “Despite its successes, their algorithm doesn’t solve every challenge raised,” says Ruslan Salakhutdinov, a computer scientist at Carnegie Mellon University, who was not involved in the study. “It doesn’t automatically handle unpracticed forms of generalization.” In other words, the training protocol helped the model excel in one type of task: learning the patterns in a fake language. But given a whole new task, it couldn’t apply the same skill. This was evident in benchmark tests, where the model failed to manage longer sequences and couldn’t grasp previously unintroduced “words.”
And crucially, every expert Scientific American spoke with noted that a neural network capable of limited generalization is very different from the holy grail of artificial general intelligence, wherein computer models surpass human capacity in most tasks. You could argue that “it’s a very, very, very small step in that direction,” Solar-Lezama says. “But we’re not talking about an AI acquiring capabilities by itself.”
From limited interactions with AI chatbots, which can present an illusion of hypercompetency, and abundant circulating hype, many people may have inflated ideas of neural networks’ powers. “Some people might find it surprising that these kinds of linguistic generalization tasks are really hard for systems like GPT-4 to do out of the box,” Solar-Lezama says. The new study’s findings, though exciting, could inadvertently serve as a reality check. “It’s really important to keep track of what these systems are capable of doing,” he says, “but also of what they can’t.”