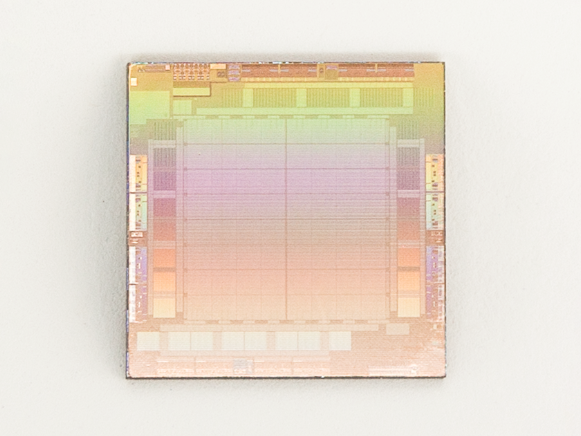
集微网消息,Facebook母公司Meta于当地时间5月18日首次官宣了自研AI运算芯片项目——MTIA,此外还有人工智能运算领域的多项进展和计划。首款芯片MTIA v1于2020年便开始设计,目前已有成品应用。
Meta基础设施部门副总裁Alexis Bjorlin表示,“建造我们自己的硬件,能够使我们便于控制技术架构的每一层,从数据中心设计到AI训练框架。”通过从水平、垂直两方面整合架构,能够推动人工智能研究的规模化发展。
Meta自研定制芯片项目的全称为“Meta Training and Inference Accelerator”(Mera训练和推理加速器),简称为MTIA。这种定制芯片采用开源芯片架构RISC-V,在类型上属于ASIC专用集成电路,Meta进行了高度定制化的设计。

Meta表示,AI技术在Meta公司的应用无处不在,包括内容理解、推送、广告排名、生成式AI等等。这些工作目前在PyTorch深度学习框架上运行,其具有一流的Python集成能力、快速的开发进度和简单的API。深度学习推荐模型(DLRM)对于改善Meta服务和应用体验尤其重要,但随着这些模型规模和复杂度的增加,对底层硬件系统的计算能力、内存容量提出了指数级的要求,此外,运算效率也急需提升。
Meta公司发现,对于目前规模的AI运算和该公司特定的工作负载,GPU的效率不高,并不是最佳选择。因此,该公司提出了设计MTIA专用加速芯片的计划,用于PyTorch框架。

第一代芯片MTIA v1于2020年开始设计,其采用台积电7nm制程工艺,运行频率800MHz,TDP仅为25W,INT8整数运算能力为102.4 TOPS,FP16浮点运算能力为51.2 TFLOPS。在架构方面,这款芯片由PE运算单元、片上缓存、片外缓存、传输接口、控制单元等组成。
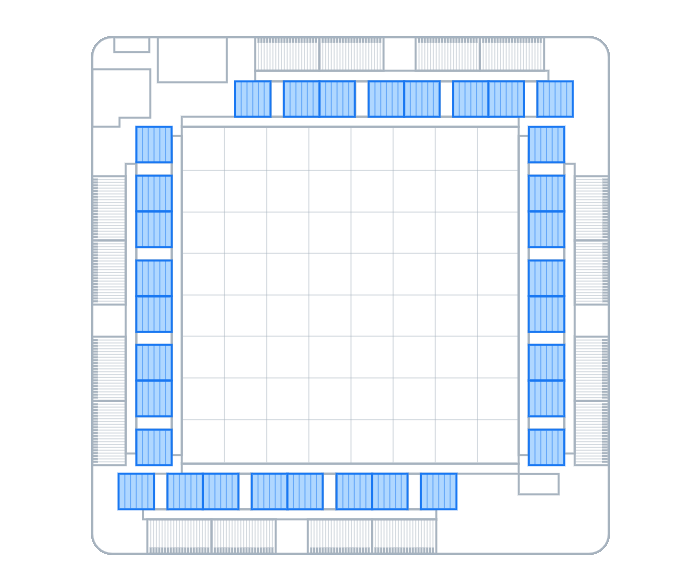
具体来看,MTIA v1使用LPDDR5作为片外DRAM内存,最高可扩展至128GB。芯片内部集成了128MB SRAM片上缓存,为所有PE单元共享,这能够为大量数据和指令的交换提供大带宽、低延迟保障。
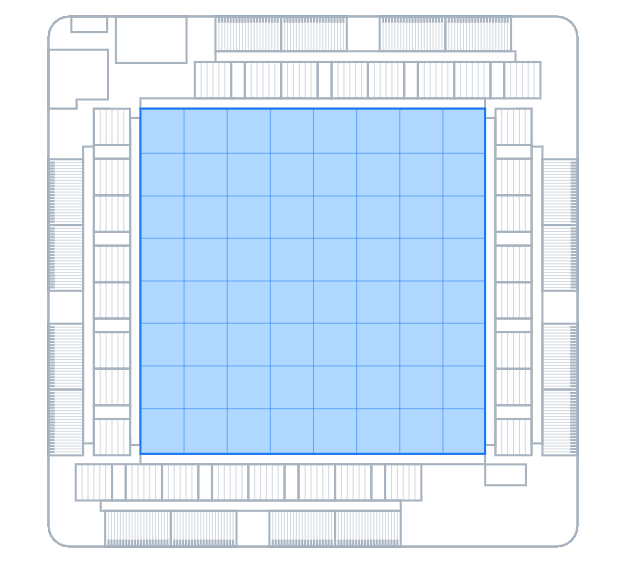
芯片中央是8×8阵列组成的64个PE运算单元,这些单元可以作为一个整体进行运算,也可以分区独立运算。每个PE运算单元均配备两个处理器内核(其中一个具有矢量扩展能力)和固定功能模块。这些单元经过优化,可以执行矩阵乘法、累加、数据移动、非线性函数运算等。处理器内核基于RISC-V开源指令集架构(ISA),并由Meta进行了大量定制,便于执行运算和控制任务。每个PE单元都具备独立的128KB SRAM缓存,用于数据高速交换,这一缓存极大提高了并行运算的效率。
MTIA v1芯片能提供线程级、数据级并行运算能力(TLP、DLP)以及指令级并行能力(ILP),此外,还允许通过众多内存请求,实现大量的内存级并行(MLP)。

在应用方面,MTIA加速芯片可安装在小型双M.2尺寸PCB上组成模块,体积非常小,便于集中整合到服务器当中。每个模块采用PCIe Gen4×8总线连接至服务器主板,与CPU进行通信。这种模块的总功耗可以低至35W。
搭载MTIA加速模块的服务器,规格来自开源的Yosemite V3,每台服务器可装载12个模块。在拓扑结构方面,模块之间的通信无需经过CPU,这样可以极大帮助不同的工作负载分布在不同的加速器上,并行运行。

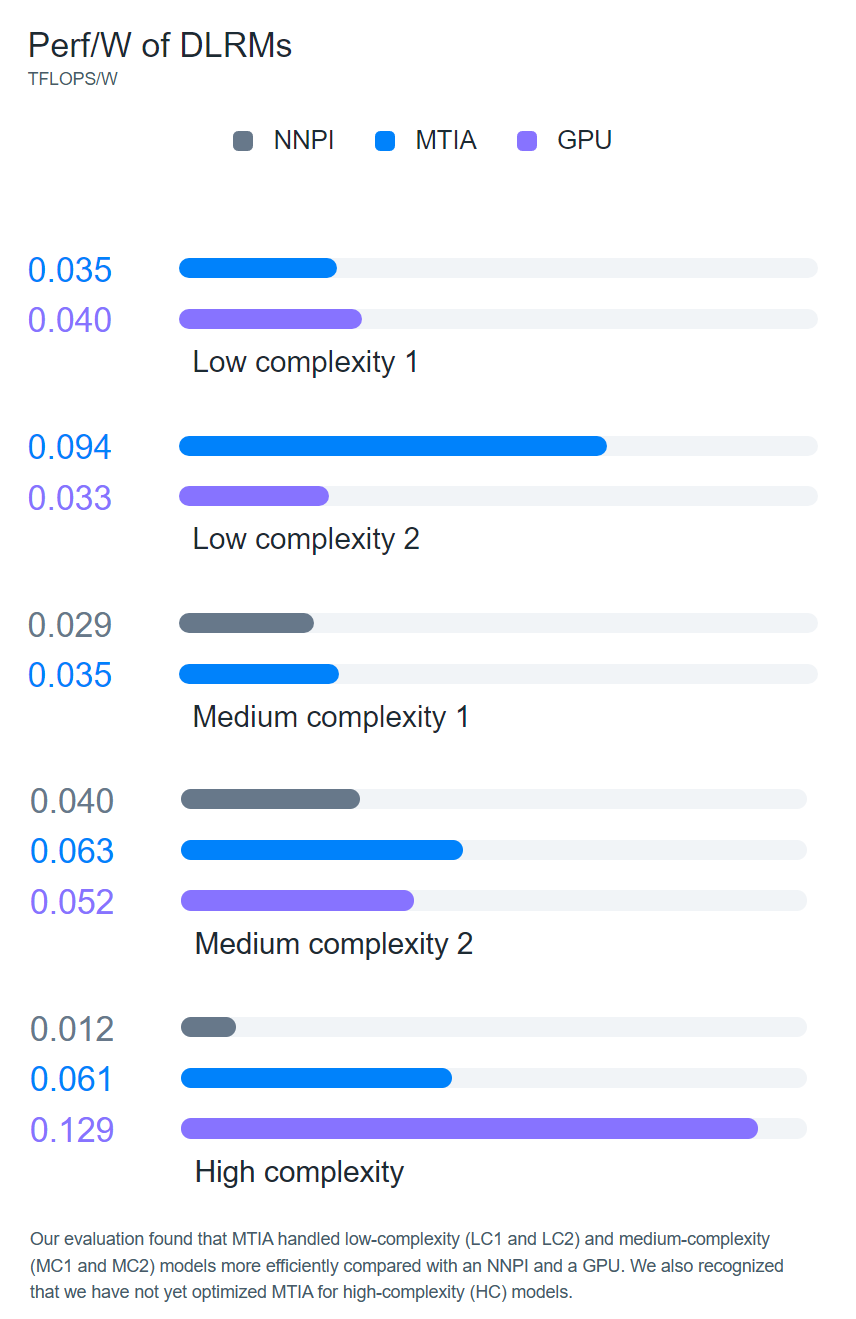
官方表示,MTIA项目的软件栈同样经过了精心研发,旨在为开发者提供高效、高性能体验。在MTIA中使用PyTorch就像在CPU、GPU上一样简单。性能方面,MTIA芯片在处理低复杂度、中复杂度模型方面可以优于传统GPU,但是在高复杂度模型方面明显落后,需要进一步优化。
Meta公司表示,未来将开发更强大的MTIA芯片,预计会在2025年推出。在将来,该公司或许会将其大部分人工智能运算都转移至MTIA,取代GPU。此外,该公司还将自研RSC AI超级计算机,用于大规模人工智能模型训练,其性能会远超目前世界上已有的超级计算机。
集微网了解到,Meta还透露除了MTIA之外,还在开发一款视频处理芯片,用于满足视频点播和直播流媒体的处理需求。
(校对/张杰)